
One of the defining themes of digital transformation is the proliferation of AI-driven insights across all enterprise business processes. With the growth of cloud data platforms, the complexity of managing big data has been radically reduced. The availability of powerful enterprise AI platforms dramatically simplify the process of building and deploying AI/ML models. And while finding good people is always hard, schools are minting more and more data scientists with the requisite data and Python skills needed to hit the ground running.
Augmented analytics (aka Augmented Intelligence / aka Decision Intelligence) incorporate AI-generated insights into mainstream business intelligence (BI) and analytics workstreams – extending the visibility of the output of data science initiatives to a broader audience. This requires organizations to scale data science programs – hardening models, building robust data pipelines that feed these models, and publishing the output of models for consumption alongside historical analytics. Operationalizing augmented analytics and scaling data science starts with breaking down silos.
The Silos that Separate BI and AI
Even though BI and data science teams are working toward similar outcomes and are working with similar data, there are three types of silos that separate these parallel worlds.
Data and Technology Silos
“Breaking down data silos” has been a rallying cry for data teams for years – driving the rise of data warehouses, data lakes and centralized cloud data platforms. Despite the massive progress, there remains data and technology silos that make it difficult for BI teams and data scientists to collaborate.
BI teams tend to think about data warehouses, query acceleration, and BI tools like Tableau and PowerBI. Data analysts leverage OLAP platforms like Microsoft SSAS and Excel PivotTables to explore business trends and develop data-driven insights on their business progress.
Data science teams apply statistical and advanced modeling techniques to identify patterns in data that can help predict the future or optimize business activity. They rely on Python scripts to move and transform data. They leverage AI/ML platforms to build their models. They think about feature stores more than data warehouses. And they are more likely to integrate data from third-party sources (e.g. foot traffic or web traffic data for retail; economic indicators for financial data scientists).
Both teams rely on the same raw data to derive insights, but they tend to think differently on the best way to organize and manipulate the data – and work with different data technologies.
People, Priorities, Culture Silos
Beyond data and technology, BI and data science programs can be separated by the organizational silos they sit in. These are most commonly different teams with different leadership, budget priorities and cultures.
BI users may sit in IT or within line of business units (not uncommonly in both with sub-silos coming into play). BI users care about delivering timely insights to business leadership. They care about fostering a data culture rooted in self service and data literacy. They direct budget priorities toward scalable data infrastructure, optimizing data pipelines, and simplifying data consumption.
Data science teams (or Decision Intelligence or Augmented Intelligence) teams are increasingly a distinct team. Data scientists are focused on exploring new modeling techniques, incorporating new data sets, and innovating on how to leverage data to gain competitive advantage.
While there are skill overlaps, these teams are typically composed of individuals with different educational backgrounds, career aspirations,personalities and hairstyles.
Language and Semantic Silos
Probably the most problematic challenge is bridging the basic semantics across these different constituencies. BI and data science teams speak a different language.
BI users talk about measures and dimensions. They discuss strategies for accelerating queries. They worry about conforming dimensions across disparate data sets. They focus on descriptive or diagnostic analytics.
Data science teams, to contrast, focus on features and feature discovery. Their models deliver predictive or prescriptive statistics.
Even so, both teams strive to bridge the language of raw data (i.e. field names, table names, metadata) to the business language of decision makers (i.e. revenue, bookings, quantities, geographies, products, etc.).
Bridging AI and BI with a Semantic Layer
With a semantic layer, you can bridge the gap between BI users and data science teams. This enables your teams to work transparently and cooperatively off the same information, and with the same goals.
A semantic layer abstracts away the complexity of underlying raw data in a virtual model. Data consumers are able to review important quantitative measures, business hierarchies, and predefined calculations in an intuitive, highly organized manner. As they request (i.e. query) data through the semantic layer platform, the “language” of their request (SQL, MDX, or DAX for BI / Python for data science) is translated to the query language of the underlying cloud platform. This way, both teams interact with the same raw data through the same set of governed data models. This simplifies both teams’ lives and ensures a single source of truth (i.e. revenue is revenue, a sales region is a sales region) regardless of the descriptive words they use. The result is a more productive and a more aligned organization.
How Augmented Analytics Fuels your Data and Analytics Flywheel
Productivity and alignment are fundamental. But it is just the starting point. Let’s examine how a semantic layer not only unites but reinforces an organization’s data. Imagine a hypothetical grocery store: instead of relying on publishing a circular of coupons, they can now track and target consumers based on data for specific price reductions.
But there’s a catch: if teams are siloed, they may have different data priorities or KPIs. For example, if the sales team sees an opportunity to run a sale on hamburger meat, and they don’t have access to logistics data that shows an upcoming meat shortage, they can’t effectively make decisions about promotions.
Data responsiveness requires cooperation and clarity. If the sales and logistics teams were united through a semantic layer, they could work together off one source of truth and build off of compound knowledge, providing a deeper bed of analytics to work from. Instead, diverse teams in this hypothetical grocery store––managing demand, logistics, and customer preferences––could develop promotions that meet all their requirements for a holistic, data-driven decision built on augmented analytics.
That helps not only the diverse teams, but the organization at large to make decisions. When teams work off one semantic layer as their source of data, they can all be attuned to the organization’s collective needs.
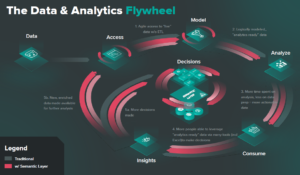
This reinforcing process helps build an exponential feedback loop, where data can become a source of actual predictions and decisions, helping guide your company without burying insights within unclear and conflicted data.
Expanding the Data Science Audience with Augmented Analytics
Ultimately, people make the decisions around your organization. A semantic layer can become a vehicle for delivering augmented analytics to a broader audience by publishing the results of data science programs through existing BI channels.
Both data science and BI users have the same basic audience: business decision makers. BI has spent decades optimizing the delivery of data insights with interactive visualization tools, reports and dashboards. Data science platforms may incorporate visualizations, but typically are not optimized for publishing to a broad audience. Most importantly, decision makers highly prefer a single, consistent source for consuming data.
By feeding data science model results back into the semantic layer, your organization can capture the same benefits they do for using a semantic layer for historical data. Decision makers can consume predictive insights alongside historical data. They can use the same governed dimensions to reliably “drill down” into the details of a prediction. As a result, your organization can foster self-service and greater literacy of data science outputs, generating a greater return on data science investments.
To learn more about how a semantic layer can unite your BI and data science teams, listen to our on-demand webinar on augmented analytics.
SHARE
RESEARCH REPORT