I recently had the opportunity to sit down for a tech talk with an extraordinary guest: Franco Patano, the lead product specialist for Databricks SQL. We had a great conversation about how a semantic layer can work with the Databricks Lakehouse Platform to deliver a Semantic Lakehouse.
The Databricks Lakehouse Platform
The vision of the Databricks Lakehouse Platform is a one-stop shop to do all your data analytics and AI workloads in the cloud without having to have a lot of disparate products stitching everything together. The platform enables a simple, open, and unified approach that provides consistency even in multi-cloud implementations.
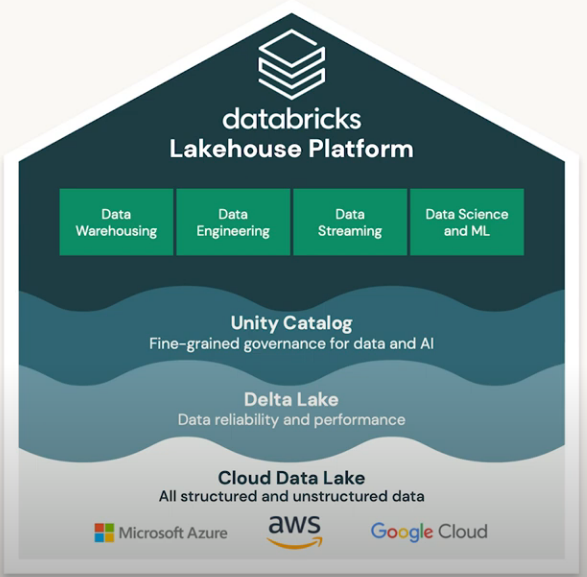
Franco walked us through a bit of the progression of Databricks from Spark to the complete data warehousing platform they offer today. What makes data warehousing on Databricks so compelling is that it provides a unified governance structure, with one single copy for all of your data that is interoperable with leading tools like AtScale’s Semantic Layer and the BI tools of your choice. It also offers serverless compute, which further abstracts away the complexities of underlying infrastructure and data sources.
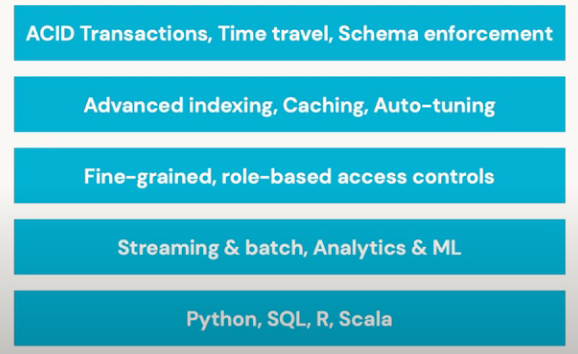
The foundation of the Lakehouse Platform is Delta Lake, an open format storage layer built for a lake-first architecture. It offers ACID-compliant transactions, advanced indexing, role-based access controls, streaming, analytics, and machine learning support.
Franco has spoken to many SQL users in his role, and one piece of feedback that comes up often is that a notebook is not the best place to develop SQL to perform analytics. Databricks SQL delivers a first-class SQL development experience right out of the box, enhanced by an intuitive GUI. A robust feature called Partner Connect also enables users to easily connect their favorite partner tools to the Databricks Lakehouse.
The Semantic Layer
The semantic layer at its core is a business representation of data that helps end-users access the information they need using a standard set of data definitions and metrics, becoming a single source of truth. This helps data consumers like business analysts, data scientists, or developers all speak the same language of the business. In turn, they can achieve agility, consistency, and control as they scale enterprise BI and AI across their organizations.
The semantic layer supports four high-level use cases:
Cloud Analytics Optimization
Organizations looking to move to a cloud platform like the Databricks Lakehouse can use a semantic layer to achieve speed of thought analytics on live cloud data and leverage agile data integration with minimal data movement.
Enterprise Metrics Store
The semantic layer enables governed enterprise metrics that can be self-served from any AI or BI tool.
Bridging AI and BI
The semantic layer provides a shared view of data assets and acts as a platform for delivering AI-generated insights to decision-makers across the business.
OLAP Modernization
Many data-driven organizations are looking to migrate their legacy OLAP SSAS models to modern, cloud-first infrastructure. The AtScale Semantic Layer facilitates this transition without any loss of functionality.
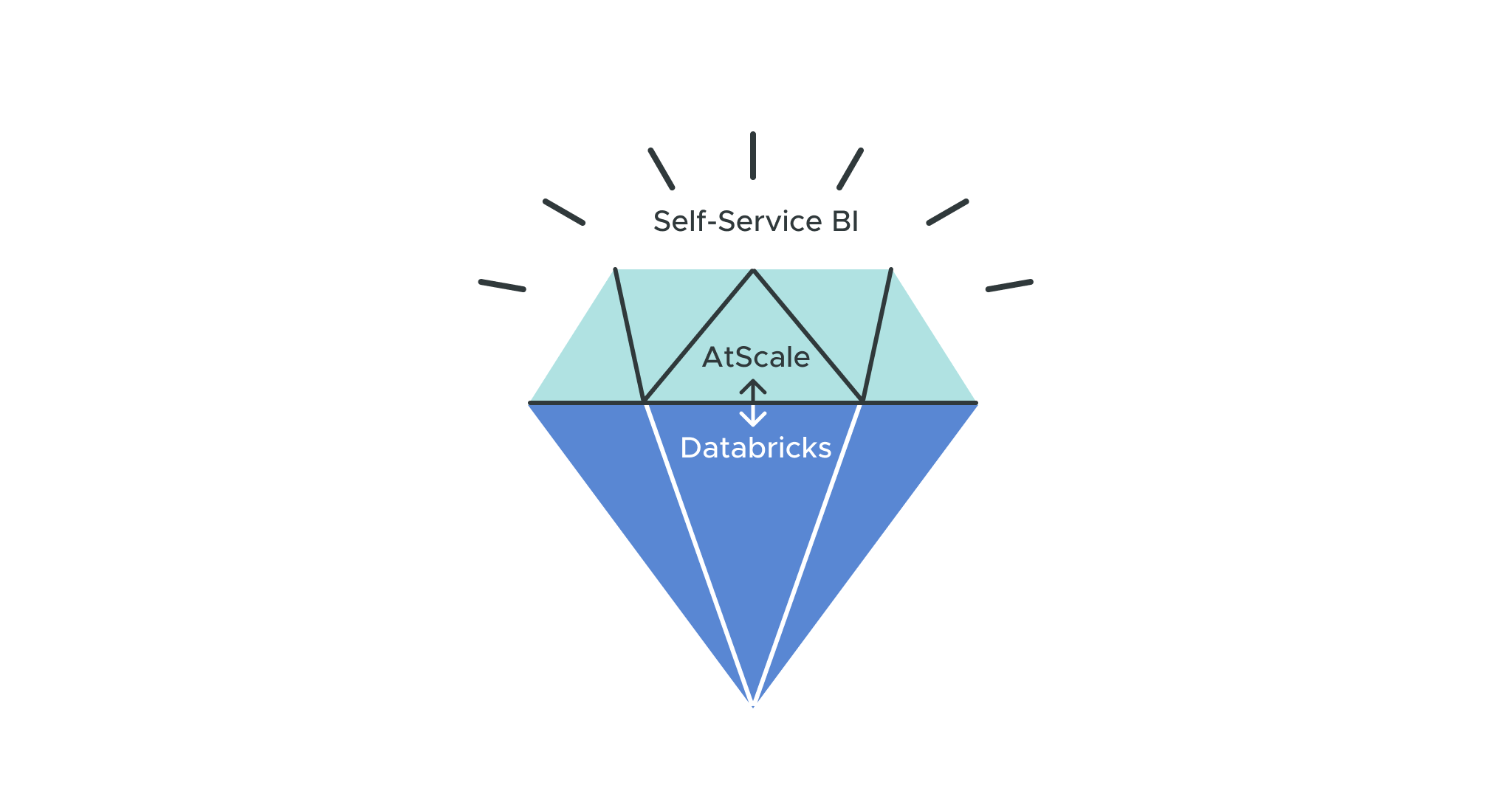
Why Databricks and AtScale?
Databricks combined with Atscale delivers self-service BI without needing an additional BI serving layer. It also provides a unique convergence of semantic and lakehouse capability that we call a Diamond Layer, providing analysis-ready data across an organization’s favorite BI, data science, and ML tools. Lastly, it facilitates critical cloud migrations and modernizes tasks that require legacy cubing technologies like Cognos and SSAS. And because AtScale creates Databricks SQL aggregate tables in the lakehouse, it connects directly to the Databricks SQL endpoints, allowing users to enjoy lightning-fast speeds regardless of how large the underlying data sources are.
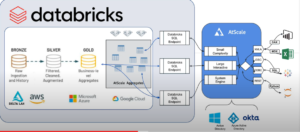
Semantic Layer Demo Built On Databricks SQL
As part of the tech talk, we went through a live demonstration of building a new model with the AtScale Design Center using Databricks SQL as the principal repository. We then published that new model and demonstrated how we could consume it with BI tools like Tableau.
First, Franco walked us through creating a SQL endpoint using Databricks. After only a few mouse clicks, he was able to give the endpoint a name and set the size.
Now it was my turn to build a semantic model from scratch. We start by adding a new cube named ‘Franco’ after our distinguished guest.
Next, we navigate through our data sources, find the sales table from our Databricks data, and drag it into our Cube Canvas.
When we double-click our sales table in the Cube Canvas, it brings us into the wrangling view, which will allow us to perform some transformations on the fly.
With the wrangling view, we can clean up our data and even create new calculations, which we demonstrate by adding a sales tax column that automatically passes to Databricks SQL.
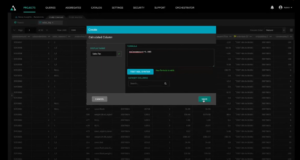
Next, we create our measures starting with sales tax. AtScale will automatically create all the correct aggregations with a few simple clicks. In just a few moments, we have three metrics: order quantity, sales amount, and sales tax.
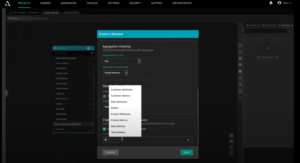
We need to think about our dimensions, so we go to our library. One drag and drop from our library has added our customer dimension to the model. We do the same for our product dimensions and dates.
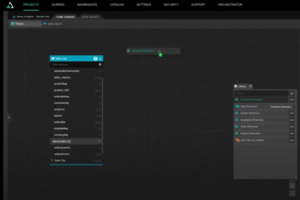
We connect our customer model to our sales log tables by creating relationships. In seconds, we have access to insightful information about our customers, including their demographics and where they made their purchases. That is possible because the customer model is made up of a model that itself contains multiple models, like geography made up of Databricks tables. This inherited governance is potent, as it eliminates much of the overhead in designing models for the business.
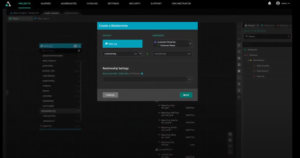
We can leverage our nested data just as quickly. We have nested data like color and style, and with a few mouse clicks, we can also turn those into dimensions. AtScale takes care of unnesting that data for you.
Our Franco model is ready to go, and we can publish it to make it available to our consumers.
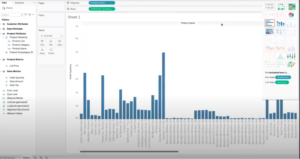
We can see all of the information from our Franco model in Tableau and make Databricks Lakehouse queries, and it took us about 10 minutes to get here. These queries are live and require no data movement.
The Semantic Layer with Databricks Enables Self-Service Analytics at Scale
This tech talk and demonstration encapsulates the power of combining the AtScale Semantic Layer with your Databricks SQL implementation. As the demonstration shows, we can create a multi-dimensional model pulling in whatever tables we need from our entire Databricks SQL datastore. We can then make live queries using the BI tools of our choice to deliver actionable insights at scale. Check out the full tech talk or schedule a live demo for your organization to learn more.
SHARE
Case Study: Vodafone Portugal Modernizes Data Analytics