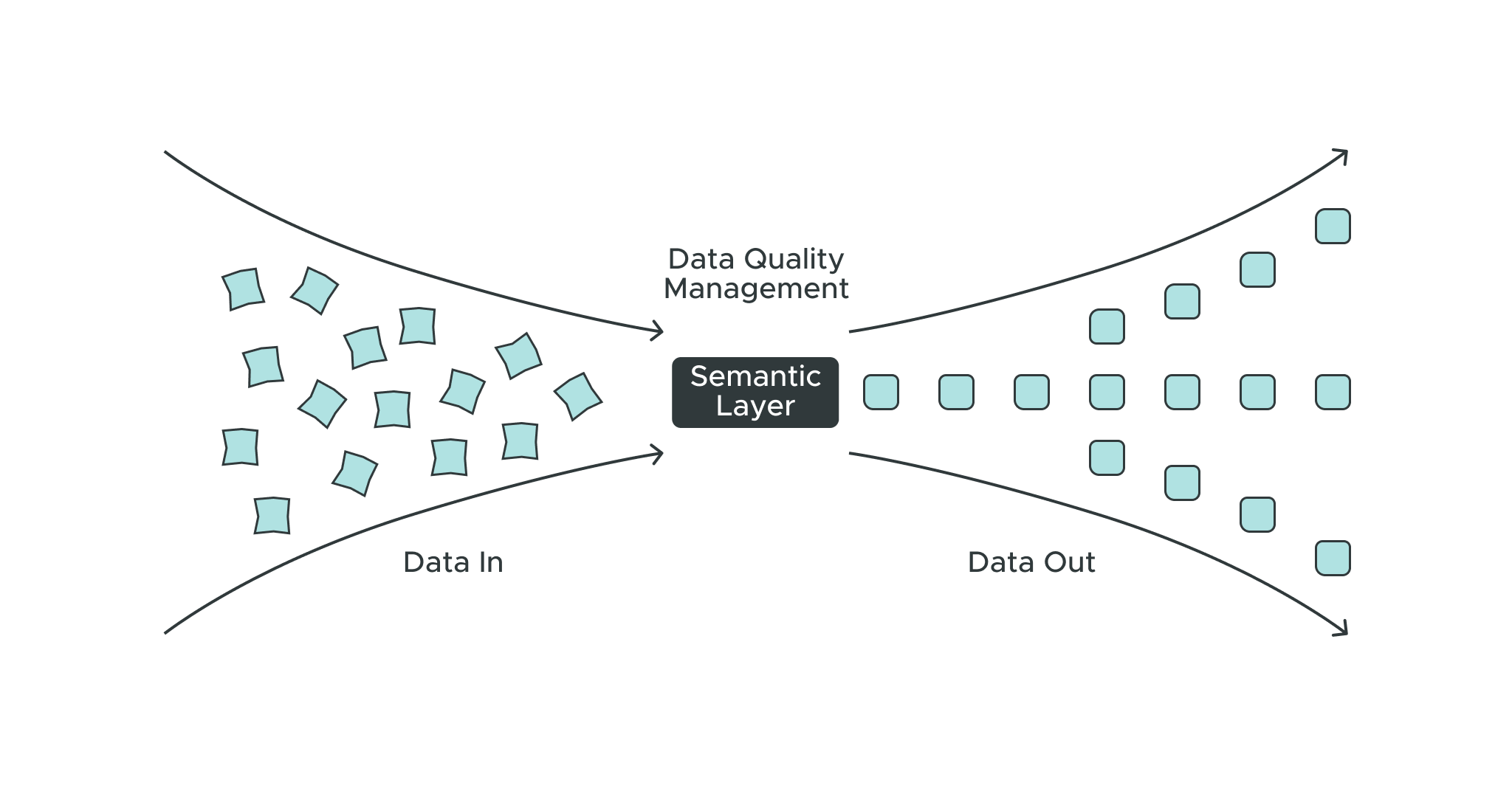
Data quality is one of the most difficult — yet essential — elements for businesses to master to achieve their operational goals. This post explores multiple facets of data quality and explains how to turn fragmented, inaccurate, and unusable data into structured, verified, and trustworthy data. It also reveals how a semantic layer removes data quality issues and enables faster and more reliable insights.
The Significance of Data Quality
Data is the primary asset for any organization that hopes to be data-driven or data-first. But what do these terms really mean? How can organizations trust their data and the analysis based on that data?
It all comes down to data quality. Business leaders are increasingly using data to drive business decisions and increase revenues. Good quality data can help businesses uncover actionable insights into market trends or validate successful strategies. But bad quality data can hamper business growth.
It’s important for businesses to understand the repercussions of bad quality data and implement processes to ensure that data is well-defined across the organization. There are many ways data quality can be compromised, which makes it painstakingly difficult for organizations to maintain data validity and conciseness at all times. While it is easier to diagnose and fix data quality issues at the origin, it’s never too late for organizations to look for ways to improve their data quality.
Data Quality in Machine Learning Models
Machine learning model predictions are useless to organizations if the underlying data doesn’t conform to high-quality data standards. Inputting high-quality data is one of the key drivers for generating trustworthy and reliable model predictions.
Within an enterprise, two major teams typically work with data:
- the data creator referred to as the data team for brevity
- the data consumers e.g. data science and analytics teams
The data team is the one who is closest to the data origin and is responsible for maintaining data quality. But this cannot be done in a silo. The data quality implementation is effective only when the data team is well-aware of multiple facets of the data, such as:
- What is the use of this data?
- What schema should it adhere to?
- Is the information consistent, complete, and accurate?
- What are the typical attribute values? How and when should we flag anomalous behavior?
- Whether the column names and their data types are consistent across different databases, etc.
Many of these questions can be answered by domain experts and end users of data. Hence, it’s important for data teams and end users to collaborate and understand varying data behavior to establish common grounds for data evaluation.
Clear communication of well-defined data is crucial to enable relevant and reliable analysis. The data quality is also subject to change throughout the process by which it was created. Quality assurance is not a one-time activity and requires a lifecycle approach to maintain high-quality data at all times. Hence, the teams must revisit such protocols periodically to conform to the expected data behavior.
Silent Failure of Machine Learning Models
The quality of input data is crucial for the success of a machine learning model. The degraded input data quality might not visibly break the code pipeline, but it leads to poor model predictions. This silent failure of the machine learning model makes it essential for enterprises to design rigorous measures and maintain data quality checkpoints.
The data team must publish a data quality report that acts as a measure of confidence for its consumers (i.e. data science teams). Based on the data quality report, the data scientist can decide whether the data contains enough quality signals to be used — and help teach — a machine learning model.
It is a known fact that data scientists spend too much time trying to fix data issues. This impacts their ability to quickly develop models and focus on forward-thinking innovations, like algorithmic modeling. Visibility into what type of data is flowing into their machine learning pipelines can help lessen the time required to fix data issues.
Let us consider a scenario where the data scientists are diagnosing the cause of degraded model predictions. As part of a root cause analysis, a data scientist traverses backward into the machine learning pipeline and investigates each model component to arrive at a fix. If the causal analysis attributes bad data quality as the cause for unexpected model behavior — it’s likely already caused a host of other issues. Not only have teams spent a great deal of time analyzing the deviations, but a lot of incorrect predictions will have already been served before the issue was flagged. A lot of time — and work — is wasted due to the delayed feedback loop.
Hence, publishing the data quality report is vital for data scientists to intervene in a timely manner and stop serving the model predictions until the data is fixed.
How Semantic Layer Reduces Data Quality Debt in Machine Learning Models
Data teams in large organizations often develop their own data quality management tools which are distinct from one another. It is important to design standard quality-control measures at business-critical junctions to alert upstream data teams to deploy the fixes at scale.
Data standardization and consolidated data definition provide a mechanism to assess and validate data quality. A quick and easy way to do this is to maintain a business glossary, but changing business dynamics that demand frequent manual updates can be difficult to keep up with.
The enterprise-wide semantic layer platform promotes data quality management and maintains a data dictionary across a growing number of complex data sources. Such well-defined and enriched data systems accelerate the speed of generating business insights and provide a competitive advantage. It provides an ecosystem with the following benefits that are invaluable to developers, as well as businesses:
- Single-point access to the data
- Context-driven data understanding
- Easy data-wrangling
- Reduces data quality debt
- Supports business-defined rules
- Consistent data dictionary
The success of any machine learning model relies heavily on the data being fed to it. Ensuring the data is accurate, consistent, and complete is critical to business-centric insights. This post explained how a sophisticated semantic layer ensures high-quality data, leading to better collaboration and increased team productivity. It also provides a technology-independent quality control system that enables easy data onboarding by building forward-compatible data systems.
SHARE
Case Study: Vodafone Portugal Modernizes Data Analytics